
Mapping Tokens to Vectors
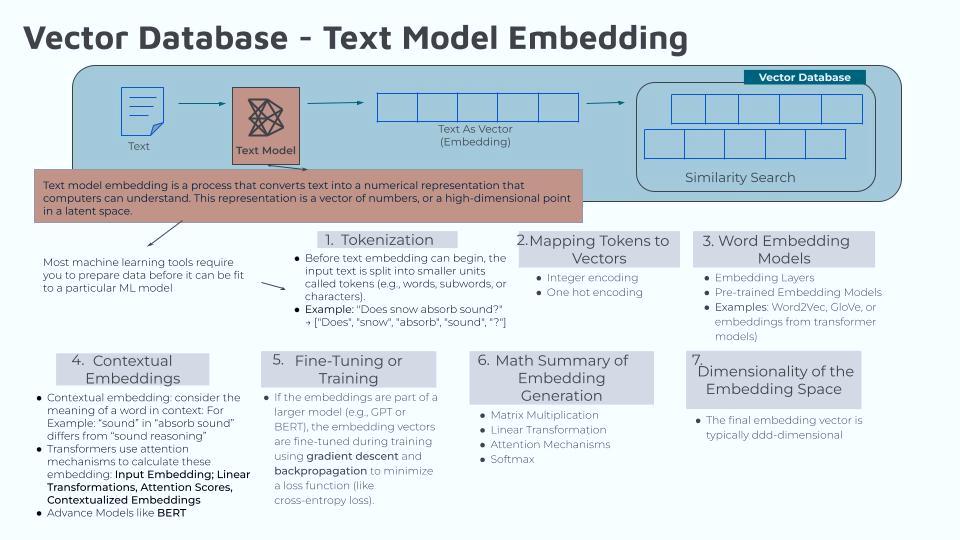
Continuing to use my AI prompt: “Does Snow Absorb Snow”…. I will write an article for each step in the Text Model Embedding process. The first step is self-explanatory, it is Tokenization. That is breaking the sentence into tokens (words and punctuation). Before text embedding can begin, the input text is split into smaller units called tokens.
Using my prompt and breaking it into tokens looks like… Tokens: [“Does”, “snow”, “absorb”, “sound”, “?”]
The next step is to map each token to a vector and this will be the main topic of this article. Each token is mapped to an initial numerical representation, often a one-hot encoding or an index. When I first read that I was so focused on ‘one-hot encoding’ that I did not pay much attention to indexing. I know in a structured dataset (or an array) the index of the first element is assigned 0, the second element is assigned 1, the third element is assigned 2, and so on. That’s how you index a structured dataset. The index allows for retrieving specific data points within a structured database. This is by referencing key values within the data, making it ideal for searching and querying organized information.
Now I do not know if ‘one-hot encoding’ is the same or similar, but doing some research I found that Indexing and ‘one-hot encoding’ are identical in that they assign a numerical value to categorical data. However, one-hot encoding creates a binary vector representation where only one element is “1” to indicate the presence of a specific category, for example [1,0,0,0] Whereas indexing simply assigns a unique integer to each category.
Using my prompt and assigning a vector to each token looks like…
“Does” ? [1,0,0,0,0]
“snow” ? [0,1,0,0,0]
“absorb” ? [0,0,1,0,0]
“sound” ? [0,0,0,1,0]
“?” ? [0,0,0,0,1]
So, in my understanding, these first two steps are straightforward…
- Break the prompt into tokens
- Assign each token into a vector (or numerical value)
The third step, word embedding models, looks to be more involved. I will post that on Wednesday and will break it into two steps if needed.
_________________________________
They say that “the best way to learn is to teach” so these articles are to help me learn and I hope others can get something from them as well. ?
______________________________________________
All articles posted Wednesdays & Saturdays by 8PM
(with additional postings here and there)