
Word Embedding Models
As a reminder, I decided to start learning about the vector database processes by focusing on the text embedding models. As I wrote in previous articles, the first two steps in this process are “tokenization” and “mapping tokens to vectors”. That is…
My AI prompt is: “Does Snow Absorb Snow”
Step 1: Tokens: [“Does”, “snow”, “absorb”, “sound”, “?”]
Step2: Assigning a vector to each token
“Does” ? [1,0,0,0,0]
“snow” ? [0,1,0,0,0]
“absorb” ? [0,0,1,0,0]
“sound” ? [0,0,0,1,0]
“?” ? [0,0,0,0,1]
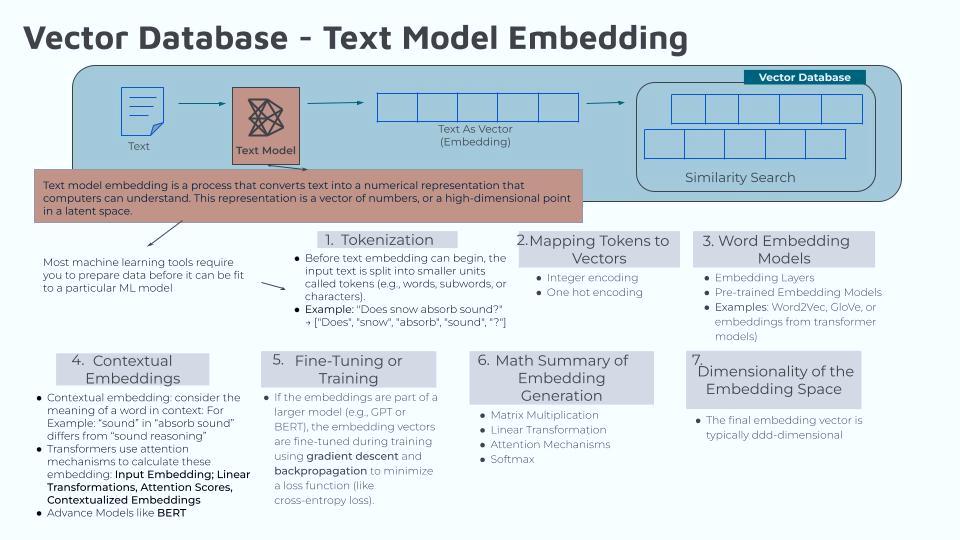
The third step is to work with word embedding models. According to Google AI, word embedding models are “statistical models representing words as vectors in a continuous space. The model learns to predict a word based on the words around it, and the resulting vectors capture the word’s meaning and position in a language”.
GeeksForGeeks defines it as “an approach for representing words and documents. Word Embedding or Word Vector is a numeric vector input that represents a word in a lower-dimensional space. It allows words with similar meanings to have a similar representation”.
The best definition of text embedding I have found would be from DataCamp: “Text embeddings are a way to convert words or phrases from text into numerical data that a machine can understand. In reading that I see that you take all the token vectors, from Step2, and do some calculations to create that numerical data.
I remember in one of the few computer science classes I took, as we were waiting for the teacher to arrive (I was always early to my classes), they were talking about their Machine Language class. After listening to them I did some research and learned a tidbit of it but I couldn’t tell you anything that I taught myself, in that regard. I said that to say this step would be interesting if nothing else.
I understand the big picture of these descriptions, however I am curious about the details. There are several existing models, or methods, such as Word2Vec, Doc2Vec, Bert, ELMo, Glove, and HuggingFace. The processes of these different text embedding models vary significantly. So looking specifically at Word2Vec and prompting ChatGPT about this model, I found the basic mathematical principles behind processing the sentence “Does Snow Absorb Snow” as such…
- Input: Tokenization
- Token to Vector
- Embedding Layer
- Context and Target
- Training: Negative Sampling
- (Example Calculation)
- Gradient Updates
Focusing on Step 3, the Embedding Layer, and leaving the other four for subsequent articles. The vectors created in Step 2 are multiplied by the embedding matrix W of size V x N, where:
- V = Vocabulary size (5 in this case)
- N = Embedding dimension (e.g., 2 or 100)
Embedding dimension, what is it? The embedding dimension looks to be a hyperparameter in Word2Vec. A hyperparameter is a configuration variable that data scientists set before training a machine learning model. Hyperparamets control how a model learns from data and can significantly impact the model’s performance.
These embedding dimensions can range from 2 to 300. The higher dimensions (200 – 300) are useful for large vocabularies and complex tasks. Whereas the lower dimensions (50 -100) are useful for simpler problems or smaller vocabularies.
Embedding matrix, what is it? I originally thought this would be straight forward but it’s taken a while to find out what ‘embedding matrix’ is and how it is calculated. I am still trying to figure all of this out, the details of it. What I have determined so far is that the “embedding matrix” is learned during the training process of a machine learning model; it starts with randomly initialized values and gets progressively refined as the model learns relationships within the data. I want to look into this further but that is what I have at this point.
But let’s take a embedding matrix that is defined at such:

Using the prompt “Does Snow Absorb”, the embeddings layer looks like the following:
- For “Does” ( [1, 0, 0] ): Embedding = [1,0,0] ? W = [0.1, 0.2]
- For “Snow” ( [0, 1, 0] ): Embedding = [0 ,1 ,0] ? W = [0.4, 0.5]]
- For “Absorb” ( [0, 0, 1] ): Embedding = [0, 0, 1] ? W = [0.8,0.3]
As I said above, I want to look into this a little further so my Wednesday article will be a continuation of the embedding layer.
______________________________________________
They say that “the best way to learn is to teach” so these articles are to help me learn and I hope others can get something from them as well. ?
All articles posted Wednesdays & Saturdays by 8PM
(with additional postings here and there))