
Introduction to Pre-Trained Language Models
To recap, I started learning about the vector database processes by focusing on the text embedding models. As I wrote in previous articles, the first three steps in this process are “tokenization”, “mapping tokens to vectors”, and “word embedding”. That is…
My AI prompt is: “Does Snow Absorb Snow”
Step 1: Tokens: [“Does”, “snow”, “absorb”, “sound”, “?”]
Step 2: Assigning a vector to each token
“Does” ? [1,0,0,0,0]
“snow” ? [0,1,0,0,0]
“absorb” ? [0,0,1,0,0]
“sound” ? [0,0,0,1,0]
“?” ? [0,0,0,0,1]
Step 3: Word Embedding, where you take the vectors created in Step 2 and multiply it by the embedding matrix of size V x N; where V=Vocabulary size & N=Embedding dimension.
The embedding dimension is a hyperparameter (a configuration variable that data scientists set before training a machine learning model), which ranges from 2 to 300. With the higher values being for large vocabularies and complex tasks.
I was still hazy on the embedding matrix so I am going to write more about it here.
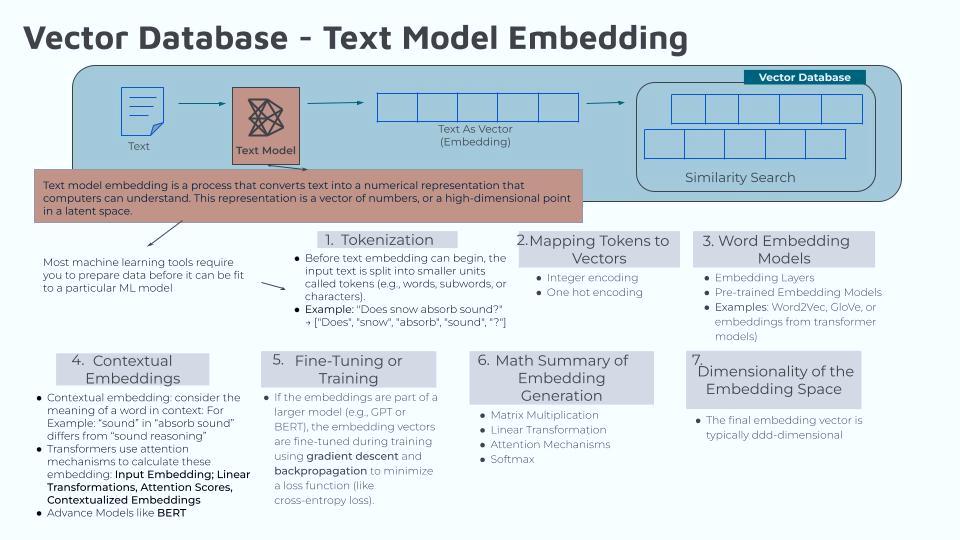
What I know now is that the “embedding matrix” is learned during the training process of a machine learning model. It starts with randomly initialized values and gets progressively refined as the model learns relationships within the data. But what specifically does all of this mean? Is “initialized values” the same as initializing in standard databases? For example (“Does”, “snow”, “absorb”, “sound”, “?”) = (0, 1, 2, 3, 4) meaning:
“Does” is initialized to 0
“Snow” is initialized to 1
“Absorb” is initialized to 2
“Sound” is initialized to 3
“?” is initialized to 4
..this is how it is done in a standard database. Is the “initialized values” the same in the vector database, using vectors? And what specifically is this “training process”?
I was able to set up an account in DeepSeek and I asked this question. According to DeepSeek there are already established Pre-Trained Language Models, such as GPT (Generative Pre-trained Transformer), BERT (Bidirectional Encoder Representations from Transformers), DistilBERT, and DeepSeek Models. It is also made clear that “training a language model from scratch is a complex and resource-intensive process”.
Now that I am looking at this, I’m reminded that this is where I stopped the first time I started learning about Vector Databases. With all that said, there are some steps to get started…
- Define my goal
- Choose a Framework & tools
- Collect and Prepare Data
- Choose a Model Architecture
- Pre-Training (If Starting from Scratch)
- Fine-Tuning (Optional)
- Evaluate the Model
- Deploy the Model
DeepSeek also provides a list of tools and libraries to get started:
- Hugging Face Transformers: Provides pre-trained models and tools for fine-tuning
- PyTorch: A flexible deep learning framework
- TensorFlow: Another popular framework for training and deployment
- Datasets: Use libraries like Hugging Face’s datasets or TensorFlow Datasets for easy access to training data
- Tokenizers: Use Hugging Face’s tokenizers library for efficient text tokenization.
According to Huggingface’s discussion board there are some state-of-the-art techniques for initializing embedding weight matrices, such as:
- PyTorch uses “normal distribution”
- Kaiming Init
- Xavier
There is a lot of information here and since I have not used, but have always been interested in using, PyTorch and TensorFlow… I think the next step will be to look into these two, along with these three state-of-the-art techniques. Maybe in the process of using them, I will be able to understand what is meant by training (in detail).
______________________________________________
They say that “the best way to learn is to teach” so these articles are to help me learn and I hope others can get something from them as well. ?
All articles posted Wednesdays & Saturdays by 8PM
(with additional postings here and there)